
Character codes

You are encouraged to solve this task according to the task description, using any language you may know.
- Task
Given a character value in your language, print its code (could be ASCII code, Unicode code, or whatever your language uses).
- Example
The character 'a' (lowercase letter A) has a code of 97 in ASCII (as well as Unicode, as ASCII forms the beginning of Unicode).
Conversely, given a code, print out the corresponding character.
11l
print(‘a’.code) // prints "97"
print(Char(code' 97)) // prints "a"360 Assembly
S/360 architecture and EBCDIC was born together. In EBCDIC, the character 'a' (lowercase letter A) has a code of 129 in decimal and '81'x in hexadecimal. To perform conversion, we use IC (insert character) and STC (store character) opcodes.
* Character codes EBCDIC 15/02/2017
CHARCODE CSECT
USING CHARCODE,R13 base register
B 72(R15) skip savearea
DC 17F'0' savearea
STM R14,R12,12(R13) prolog
ST R13,4(R15) " <-
ST R15,8(R13) " ->
LR R13,R15 " addressability
* Character to Decimal
SR R1,R1 r1=0
IC R1,=C'a' insert character 'a'
XDECO R1,PG
XPRNT PG,L'PG print -> 129
* Hexadecimal to character
SR R1,R1 r1=0
IC R1,=X'81' insert character X'81'
STC R1,CHAR store character r1
XPRNT CHAR,L'CHAR print -> 'a'
* Decimal to character
LH R1,=H'129' r1=129
STC R1,CHAR store character r1
XPRNT CHAR,L'CHAR print -> 'a'
*
XDUMP CHAR,L'CHAR dump -> X'81'
*
RETURN L R13,4(0,R13) epilog
LM R14,R12,12(R13) " restore
XR R15,R15 " rc=0
BR R14 exit
PG DS CL12
CHAR DS CL1
YREGS
END CHARCODE- Output:
129 a a
68000 Assembly
The printing routine only understands ASCII characters as codes anyway, so the "given a code produce its character" part is trivial.
The PrintChar routine is omitted for brevity. It converts the two cursor variables to a FIX layer address and outputs the character using the NEOGEO's FIX layer (the layer where text is displayed). Characters are stored in ROM and arranged in ASCII order.
JSR ResetCoords ;RESET TYPING CURSOR
MOVE.B #'A',D1
MOVE.W #25,D2
MOVE.B #0,(softCarriageReturn) ;new line takes the cursor to left edge of screen.
jsr PrintAllTheCodes
jsr ResetCoords
MOVE.B #8,(Cursor_X)
MOVE.B #'a',D1
MOVE.W #25,D2
MOVE.B #8,(softCarriageReturn)
;set the writing cursor to column 3 of the screen
;so we don't erase the old output.
jsr PrintAllTheCodes
forever:
bra forever
PrintAllTheCodes:
MOVE.B D1,D0
jsr PrintChar ;print the character as-is
MOVE.B #" ",D0
jsr PrintChar
MOVE.B #"=",D0
jsr PrintChar
MOVE.B #" ",D0
jsr PrintChar
MOVE.B D1,D0 ;get ready to print the code
JSR UnpackNibbles8
SWAP D0
ADD.B #$30,D0
JSR PrintChar
SWAP D0
CMP.B #10,D0
BCS noCorrectHex
ADD.B #$07,D0
noCorrectHex:
ADD.B #$30,D0
JSR PrintChar
MOVE.B (softCarriageReturn),D0
JSR doNewLine2 ;new line, with D0 as the carraige return point.
ADDQ.B #1,D1
DBRA D2,PrintAllTheCodes
rts
UnpackNibbles8:
; INPUT: D0 = THE VALUE YOU WISH TO UNPACK.
; HIGH NIBBLE IN HIGH WORD OF D0, LOW NIBBLE IN LOW WORD. SWAP D0 TO GET THE OTHER HALF.
pushWord D1
CLR.W D1
MOVE.B D0,D1
CLR.L D0
MOVE.B D1,D0 ;now D0 = D1 = $000000II, where I = input
AND.B #$F0,D0 ;chop off bottom nibble
LSR.B #4,D0 ;downshift top nibble into bottom nibble of the word
SWAP D0 ;store in high word
AND.B #$0F,D1 ;chop off bottom nibble
MOVE.B D1,D0 ;store in low word
popWord D1
rtsOutput can be seen here.
AArch64 Assembly
/* ARM assembly AARCH64 Raspberry PI 3B */
/* program character64.s */
/*******************************************/
/* Constantes file */
/*******************************************/
/* for this file see task include a file in language AArch64 assembly*/
.include "../includeConstantesARM64.inc"
/*******************************************/
/* Initialized data */
/*******************************************/
.data
szMessCodeChar: .asciz "The code of character is : @ \n"
/*******************************************/
/* UnInitialized data */
/*******************************************/
.bss
sZoneconv: .skip 32
/*******************************************/
/* code section */
/*******************************************/
.text
.global main
main: // entry of program
mov x0,'A'
ldr x1,qAdrsZoneconv
bl conversion10S
ldr x0,qAdrszMessCodeChar
ldr x1,qAdrsZoneconv
bl strInsertAtCharInc // insert result at @ character
bl affichageMess
mov x0,'a'
ldr x1,qAdrsZoneconv
bl conversion10S
ldr x0,qAdrszMessCodeChar
ldr x1,qAdrsZoneconv
bl strInsertAtCharInc // insert result at @ character
bl affichageMess
mov x0,'1'
ldr x1,qAdrsZoneconv
bl conversion10S
ldr x0,qAdrszMessCodeChar
ldr x1,qAdrsZoneconv
bl strInsertAtCharInc // insert result at @ character
bl affichageMess
100: // standard end of the program */
mov x0,0 // return code
mov x8,EXIT // request to exit program
svc 0 // perform the system call
qAdrsZoneconv: .quad sZoneconv
qAdrszMessCodeChar: .quad szMessCodeChar
/********************************************************/
/* File Include fonctions */
/********************************************************/
/* for this file see task include a file in language AArch64 assembly */
.include "../includeARM64.inc"ABAP
In ABAP you must first cast the character to a byte field and back to a number in order to get its ASCII value.
report zcharcode
data: c value 'A', n type i.
field-symbols <n> type x.
assign c to <n> casting.
move <n> to n.
write: c, '=', n left-justified.
- Output:
A = 65
ACL2
Similar to Common Lisp:
(cw "~x0" (char-code #\a))
(cw "~x0" (code-char 97))
Action!
PROC Main()
CHAR c=['a]
BYTE b=[97]
Put(c) Put('=) PrintBE(c)
PrintB(b) Put('=) Put(b)
RETURN- Output:
Screenshot from Atari 8-bit computer
{kind=link}
a=97 97=a
ActionScript
In ActionScript, you cannot take the character code of a character directly. Instead you must create a string and call charCodeAt with the character's position in the string as a parameter.
trace(String.fromCharCode(97)); //prints 'a'
trace("a".charCodeAt(0));//prints '97'Ada
with Ada.Text_IO; use Ada.Text_IO;
procedure Char_Code is
begin
Put_Line (Character'Val (97) & " =" & Integer'Image (Character'Pos ('a')));
end Char_Code;
The predefined language attributes S'Pos and S'Val for every discrete subtype, and Character is such a type, yield the position of a value and value by its position correspondingly.
- Output:
a = 97
Aime
# prints "97"
o_integer('a');
o_byte('\n');
# prints "a"
o_byte(97);
o_byte('\n');ALGOL 68
In ALGOL 68 the format $g$ is type aware, hence the type conversion operators abs & repr are used to set the type.
main:(
printf(($gl$, ABS "a")); # for ASCII this prints "+97" EBCDIC prints "+129" #
printf(($gl$, REPR 97)) # for ASCII this prints "a"; EBCDIC prints "/" #
)Character conversions may be available in the standard prelude so that when a foreign tape is mounted, the characters will be converted transparently as the tape's records are read.
FILE tape;
INT errno = open(tape, "/dev/tape1", stand out channel)
make conv(tape, ebcdic conv);
FOR record DO getf(tape, ( ~ )) OD; ~ # etc ... #Every channel has an associated standard character conversion that can be determined using the stand conv query routine and then the conversion applied to a particular file/tape. eg.
make conv(tape, stand conv(stand out channel))ALGOL W
begin
% display the character code of "a" (97 in ASCII) %
write( decode( "a" ) );
% display the character corresponding to 97 ("a" in ASCII) %
write( code( 97 ) );
end.APL
In GNU APL and Dyalog, ⎕UCS with an integer returns the corresponding Unicode character:
⎕UCS 97
a
and ⎕UCS with a character returns the corresponding code:
⎕UCS 'a'
97
Like most things in APL, ⎕UCS can also be used with an array or with a string (which is an array of characters):
⎕UCS 65 80 76
APL
⎕UCS 'Hello, world!'
72 101 108 108 111 44 32 119 111 114 108 100 33
AppleScript
log(id of "a")
log(id of "aA")
- Output:
(*97*) (*97, 65*)
The converse instruction is character id — or either of its synonyms string id and Unicode text id. Because of a bug admitted to in Apple's AppleScript Language Guide, the expression text id, which one might expect to work, can't be used.
character id 97
--> "a"
character id {72, 101, 108, 108, 111, 33}
--> "Hello!"
string id {72, 101, 108, 108, 111, 33}
--> "Hello!"
Unicode text id {72, 101, 108, 108, 111, 33}
--> "Hello!"
ARM Assembly
/* ARM assembly Raspberry PI */
/* program character.s */
/* Constantes */
.equ STDOUT, 1 @ Linux output console
.equ EXIT, 1 @ Linux syscall
.equ WRITE, 4 @ Linux syscall
/* Initialized data */
.data
szMessCodeChar: .ascii "The code of character is :"
sZoneconv: .fill 12,1,' '
szCarriageReturn: .asciz "\n"
/* UnInitialized data */
.bss
/* code section */
.text
.global main
main: /* entry of program */
push {fp,lr} /* saves 2 registers */
mov r0,#'A'
ldr r1,iAdrsZoneconv
bl conversion10S
ldr r0,iAdrszMessCodeChar
bl affichageMess
mov r0,#'a'
ldr r1,iAdrsZoneconv
bl conversion10S
ldr r0,iAdrszMessCodeChar
bl affichageMess
mov r0,#'1'
ldr r1,iAdrsZoneconv
bl conversion10S
ldr r0,iAdrszMessCodeChar
bl affichageMess
100: /* standard end of the program */
mov r0, #0 @ return code
pop {fp,lr} @restaur 2 registers
mov r7, #EXIT @ request to exit program
swi 0 @ perform the system call
iAdrsZoneconv: .int sZoneconv
iAdrszMessCodeChar: .int szMessCodeChar
/******************************************************************/
/* display text with size calculation */
/******************************************************************/
/* r0 contains the address of the message */
affichageMess:
push {fp,lr} /* save registres */
push {r0,r1,r2,r7} /* save others registers */
mov r2,#0 /* counter length */
1: /* loop length calculation */
ldrb r1,[r0,r2] /* read octet start position + index */
cmp r1,#0 /* if 0 its over */
addne r2,r2,#1 /* else add 1 in the length */
bne 1b /* and loop */
/* so here r2 contains the length of the message */
mov r1,r0 /* address message in r1 */
mov r0,#STDOUT /* code to write to the standard output Linux */
mov r7, #WRITE /* code call system "write" */
swi #0 /* call systeme */
pop {r0,r1,r2,r7} /* restaur others registers */
pop {fp,lr} /* restaur des 2 registres */
bx lr /* return */
/***************************************************/
/* conversion register signed décimal */
/***************************************************/
/* r0 contient le registre */
/* r1 contient l adresse de la zone de conversion */
conversion10S:
push {r0-r5,lr} /* save des registres */
mov r2,r1 /* debut zone stockage */
mov r5,#'+' /* par defaut le signe est + */
cmp r0,#0 /* nombre négatif ? */
movlt r5,#'-' /* oui le signe est - */
mvnlt r0,r0 /* et inversion en valeur positive */
addlt r0,#1
mov r4,#10 /* longueur de la zone */
1: /* debut de boucle de conversion */
bl divisionpar10 /* division */
add r1,#48 /* ajout de 48 au reste pour conversion ascii */
strb r1,[r2,r4] /* stockage du byte en début de zone r5 + la position r4 */
sub r4,r4,#1 /* position précedente */
cmp r0,#0
bne 1b /* boucle si quotient different de zéro */
strb r5,[r2,r4] /* stockage du signe à la position courante */
subs r4,r4,#1 /* position précedente */
blt 100f /* si r4 < 0 fin */
/* sinon il faut completer le debut de la zone avec des blancs */
mov r3,#' ' /* caractere espace */
2:
strb r3,[r2,r4] /* stockage du byte */
subs r4,r4,#1 /* position précedente */
bge 2b /* boucle si r4 plus grand ou egal a zero */
100: /* fin standard de la fonction */
pop {r0-r5,lr} /*restaur desregistres */
bx lr
/***************************************************/
/* division par 10 signé */
/* Thanks to http://thinkingeek.com/arm-assembler-raspberry-pi/*
/* and http://www.hackersdelight.org/ */
/***************************************************/
/* r0 contient le dividende */
/* r0 retourne le quotient */
/* r1 retourne le reste */
divisionpar10:
/* r0 contains the argument to be divided by 10 */
push {r2-r4} /* save registers */
mov r4,r0
ldr r3, .Ls_magic_number_10 /* r1 <- magic_number */
smull r1, r2, r3, r0 /* r1 <- Lower32Bits(r1*r0). r2 <- Upper32Bits(r1*r0) */
mov r2, r2, ASR #2 /* r2 <- r2 >> 2 */
mov r1, r0, LSR #31 /* r1 <- r0 >> 31 */
add r0, r2, r1 /* r0 <- r2 + r1 */
add r2,r0,r0, lsl #2 /* r2 <- r0 * 5 */
sub r1,r4,r2, lsl #1 /* r1 <- r4 - (r2 * 2) = r4 - (r0 * 10) */
pop {r2-r4}
bx lr /* leave function */
bx lr /* leave function */
.Ls_magic_number_10: .word 0x66666667Arturo
print to :integer first "a"
print to :integer `a`
print to :char 97
- Output:
97 97 a
AutoHotkey
MsgBox % Chr(97)
MsgBox % Asc("a")
AWK
AWK has no built-in way to convert a character into ASCII (or whatever) code; but a function that does so can be easily built using an associative array (where the keys are the characters). The opposite can be done using printf (or sprintf) with %c
function ord(c)
{
return chmap[c]
}
BEGIN {
for(i=0; i < 256; i++) {
chmap[sprintf("%c", i)] = i
}
print ord("a"), ord("b")
printf "%c %c\n", 97, 98
s = sprintf("%c%c", 97, 98)
print s
}
Axe
Disp 'a'▶Dec,i
Disp 97▶Char,iBabel
'abcdefg' str2ar
{%d nl <<} eachar- Output:
97 98 99 100 101 102 103
(98 97 98 101 108) ls2lf ar2str nl <<- Output:
babel
BASIC
charCode = 97
char = "a"
PRINT CHR$(charCode) 'prints a
PRINT ASC(char) 'prints 97
On the ZX Spectrum string variable names must be a single letter but numeric variables can be multiple characters:
10 LET c = 97: REM c is a character code
20 LET d$ = "b": REM d$ holds the character
30 PRINT CHR$(c): REM this prints a
40 PRINT CODE(d$): REM this prints 98Applesoft BASIC
CHR$(97) is used in place of "a" because on the older model Apple II, lower case is difficult to input.
?CHR$(97)"="ASC(CHR$(97))
- Output:
a=97
Output as it appears on the text display on the Apple II and Apple II plus, with the original text character ROM:
!=97
BaCon
' ASCII
c$ = "$"
PRINT c$, ": ", ASC(c$)
' UTF-8
uc$ = "€"
PRINT uc$, ": ", UCS(uc$), ", ", UCS(c$)
- Output:
$: 36 €: 8364, 36
Chipmunk Basic
10 print "a - > ";asc("a")
20 print "98 -> ";chr$(98)
Commodore BASIC
Commodore BASIC uses PETSCII code for its character set.
10 CH = 65: REM IN PETSCII CODE FOR 'A' IS 65
20 D$ = "B": REM D$ HOLDS THE CHARACTER 'B'
30 PRINT CHR$(CH): REM THIS PRINTS 'A'
40 PRINT ASC(D$): REM THIS PRINTS 66- Output:
A 66
GW-BASIC
10 PRINT "a - > "; ASC("a")
20 PRINT "98 -> "; CHR$(98)
IS-BASIC
100 PRINT ORD("A")
110 PRINT CHR$(65)MSX Basic
10 PRINT "a - > "; ASC("a")
20 PRINT "98 -> "; CHR$(98)
QBasic
PRINT "a - > "; ASC("a")
PRINT "98 -> "; CHR$(98)
Sinclair ZX81 BASIC
10 REM THE ZX81 USES ITS OWN NON-ASCII CHARACTER SET
20 REM WHICH DOES NOT INCLUDE LOWER-CASE LETTERS
30 PRINT CODE "A"
40 PRINT CHR$ 38
- Output:
38 A
SmallBASIC
Print "a -> "; Asc("a")
Print "98 -> "; Chr(98)
True BASIC
PRINT "a - > "; ord("a")
PRINT "98 -> "; chr$(98)
END
XBasic
PROGRAM "Character codes"
VERSION "0.0000"
DECLARE FUNCTION Entry ()
FUNCTION Entry ()
PRINT "a - >"; ASC("a")
PRINT "98 -> "; CHR$(98)
END FUNCTION
END PROGRAM
Yabasic
print "a - > ", asc("a")
print "98 -> ", chr$(98)BASIC256
# ASCII char
charCode = 97
char$ = "a"
print chr(97) #prints a
print asc("a") #prints 97
# Unicode char
charCode = 960
char$ = "π"
print chr(960) #prints π
print asc("π") #prints 960- Output:
a 97 π 960
Batch File
@echo off
:: Supports all ASCII characters and codes from 34-126 with the exceptions of:
:: 38 &
:: 60 <
:: 62 >
:: 94 ^
:: 124 |
:_main
call:_toCode a
call:_toChar 97
pause>nul
exit /b
:_toCode
setlocal enabledelayedexpansion
set codecount=32
for /l %%i in (33,1,126) do (
set /a codecount+=1
cmd /c exit %%i
if %1==!=exitcodeAscii! (
echo !codecount!
exit /b
)
)
:_toChar
setlocal
cmd /c exit %1
echo %=exitcodeAscii%
exit /b- Input:
toCode a toChar 97
- Output:
97 a
BBC BASIC
charCode = 97
char$ = "a"
PRINT CHR$(charCode) : REM prints a
PRINT ASC(char$) : REM prints 97
Befunge
The instruction . will output as an integer. , will output as ASCII character.
"a". 99*44*+, @
BQN
BQN's character arithmetic makes it easy to convert between numbers and characters. Since arithmetic generalizes to arrays, the same function works for both integers and arrays. Here, only the conversion from number to character is defined, since it can be automatically inverted with Undo (⁼): the inverse simply subtracts @.
FromCharCode ← @⊸+
@⊸+
FromCharCode 97
'a'
FromCharCode 97‿67‿126
"aC~"
FromCharCode⁼ 'a'
97
Bracmat
( put
$ ( str
$ ( "\nLatin a
ISO-9959-1: "
asc$a
" = "
chr$97
"
UTF-8: "
utf$a
" = "
chu$97
\n
"Cyrillic а (UTF-8): "
utf$а
" = "
chu$1072
\n
)
)
)- Output:
Latin a
ISO-9959-1: 97 = a
UTF-8: 97 = a
Cyrillic а (UTF-8): 1072 = а
C
char is already an integer type in C, and it gets automatically promoted to int. So you can use a character where you would otherwise use an integer. Conversely, you can use an integer where you would normally use a character, except you may need to cast it, as char is smaller.
#include <stdio.h>
int main() {
printf("%d\n", 'a'); /* prints "97" */
printf("%c\n", 97); /* prints "a"; we don't have to cast because printf is type agnostic */
return 0;
}
C#
C# represents strings and characters internally as Unicode, so casting a char to an int returns its Unicode character encoding.
using System;
namespace RosettaCode.CharacterCode
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine((int) 'a'); //Prints "97"
Console.WriteLine((char) 97); //Prints "a"
}
}
}
C++
char is already an integer type in C++, and it gets automatically promoted to int. So you can use a character where you would otherwise use an integer. Conversely, you can use an integer where you would normally use a character, except you may need to cast it, as char is smaller.
In this case, the output operator << is overloaded to handle integer (outputs the decimal representation) and character (outputs just the character) types differently, so we need to cast it in both cases.
#include <iostream>
int main() {
std::cout << (int)'a' << std::endl; // prints "97"
std::cout << (char)97 << std::endl; // prints "a"
return 0;
}
Clojure
(print (int \a)) ; prints "97"
(print (char 97)) ; prints \a
; Unicode is also available, as Clojure uses the underlying java Strings & chars
(print (int \π)) ; prints 960
(print (char 960)) ; prints \π
; use String because char in Java can't represent characters outside Basic Multilingual Plane
(print (.codePointAt "𝅘𝅥𝅮" 0)) ; prints 119136
(print (String. (int-array 1 119136) 0 1)) ; prints 𝅘𝅥𝅮
CLU
start_up = proc ()
po: stream := stream$primary_output()
% To turn a character code into an integer, use char$c2i
% (but then to print it, it needs to be turned into a string first
% with int$unparse)
stream$putl(po, int$unparse( char$c2i( 'a' ) ) ) % prints '97'
% To turn an integer into a character code, use char$i2c
stream$putc(po, char$i2c( 97 ) ); % prints 'a'
end start_up- Output:
97 a
COBOL
Tested with GnuCOBOL on an ASCII based GNU/Linux system. Running this code on EBCDIC native hardware would display a control code and 000000093.
identification division.
program-id. character-codes.
remarks. COBOL is an ordinal language, first is 1.
remarks. 42nd ASCII code is ")" not, "*".
procedure division.
display function char(42)
display function ord('*')
goback.
end program character-codes.
- Output:
prompt$ cobc -xj character-codes.cob ) 000000043
CoffeeScript
CoffeeScript transcompiles to JavaScript, so it uses the JS standard library.
console.log 'a'.charCodeAt 0 # 97
console.log String.fromCharCode 97 # a
Common Lisp
(princ (char-code #\a)) ; prints "97"
(princ (code-char 97)) ; prints "a"
Component Pascal
BlackBox Component Builder
PROCEDURE CharCodes*;
VAR
c : CHAR;
BEGIN
c := 'A';
StdLog.Char(c);StdLog.String(":> ");StdLog.Int(ORD(c));StdLog.Ln;
c := CHR(3A9H);
StdLog.Char(c);StdLog.String(":> ");StdLog.Int(ORD(c));StdLog.Ln
END CharCodes;- Output:
A:> 65 Ω:> 937
D
void main() {
import std.stdio, std.utf;
string test = "a";
size_t index = 0;
// Get four-byte utf32 value for index 0.
writefln("%d", test.decode(index));
// 'index' has moved to next character input position.
assert(index == 1);
}
- Output:
97
Dc
A dc program cannot look into strings. But it can convert numeric values into single char strings or print numeric codes directly:
97P- Output:
a
Delphi
Example from Studio 2006.
program Project1;
{$APPTYPE CONSOLE}
uses
SysUtils;
var
aChar:Char;
aCode:Byte;
uChar:WideChar;
uCode:Word;
begin
aChar := Chr(97); Writeln(aChar);
aCode := Ord(aChar); Writeln(aCode);
uChar := WideChar(97); Writeln(uChar);
uCode := Ord(uChar); Writeln(uCode);
Readln;
end.
Draco
proc nonrec main() void:
writeln(pretend(97, char)); /* prints "a" */
writeln(pretend('a', byte)); /* prints 97 */
corpDWScript
PrintLn(Ord('a'));
PrintLn(Chr(97));
Dyalect
print('a'.Order())
print(Char(97))E
? 'a'.asInteger()
# value: 97
? <import:java.lang.makeCharacter>.asChar(97)
# value: 'a'EasyLang
print strcode "a"
print strchar 97
Ecstasy
module CharacterCodes {
@Inject Console console;
void run() {
for (Char char : ['\0', '\d', 'A', '$', '¢', '~', '˜']) {
// character to its integer value
UInt32 codepoint = char.codepoint;
// integer value back to its character value
Char fromCodePoint = codepoint.toChar(); // or: "new Char(codepoint)"
console.print($|Character {char.quoted()}:\
| Unicode codepoint={char.codepoint},\
| ASCII={char.ascii},\
| UTF8 bytes={char.utf8()},\
| char from codepoint={fromCodePoint.quoted()}
);
}
}
}
- Output:
Character '\0': Unicode codepoint=0, ASCII=True, UTF8 bytes=0x00, char from codepoint='\0' Character '\d': Unicode codepoint=127, ASCII=True, UTF8 bytes=0x7F, char from codepoint='\d' Character 'A': Unicode codepoint=65, ASCII=True, UTF8 bytes=0x41, char from codepoint='A' Character '$': Unicode codepoint=36, ASCII=True, UTF8 bytes=0x24, char from codepoint='$' Character '¢': Unicode codepoint=162, ASCII=False, UTF8 bytes=0xC2A2, char from codepoint='¢' Character '~': Unicode codepoint=126, ASCII=True, UTF8 bytes=0x7E, char from codepoint='~' Character '˜': Unicode codepoint=732, ASCII=False, UTF8 bytes=0xCB9C, char from codepoint='˜'
Eiffel
All characters are of the type CHARACTER_8 (ASCII encoding) or CHARACTER_32 (Unicode encoding). CHARACTER is a synonym for either of these two (depending on the compiler option). Characters can be assigned using character literals (a single character enclosed in single quotes) or code value notation (of the form '%/value/' where value is an integer literal of any of the recognized forms).
class
APPLICATION
inherit
ARGUMENTS
create
make
feature {NONE} -- Initialization
make
-- Run application.
local
c8: CHARACTER_8
c32: CHARACTER_32
do
c8 := '%/97/' -- using code value notation
c8 := '%/0x61/' -- same as above, but using hexadecimal literal
print(c8.natural_32_code) -- prints "97"
print(c8) -- prints the character "a"
c32 := 'a' -- using character literal
print(c32.natural_32_code) -- prints "97"
print(c32) -- prints "U+00000061"
--c8 := 'π' -- compile-time error (c8 does not have enough range)
c32 := 'π' -- assigns Unicode value 960
end
end
Limitations: There is no "put_character_32" feature for standard io (FILE class), so there appears to be no way to print Unicode characters.
Elena
ELENA 6.x :
import extensions;
public program()
{
var ch := $97;
console.printLine(ch);
console.printLine(ch.toInt())
}- Output:
a 97
Elixir
A String in Elixir is a UTF-8 encoded binary.
iex(1)> code = ?a
97
iex(2)> to_string([code])
"a"
Emacs Lisp
(string-to-char "a") ;=> 97
(format "%c" 97) ;=> "a"
EMal
^|ord and chr work with Unicode code points|^
writeLine(ord("a")) # prints "97"
writeLine(chr(97)) # prints "a"
writeLine(ord("π")) # prints "960"
writeLine(chr(960)) # prints "π"
writeLine()
var cps = int[]
for each var c in text["a", "π", "字", "🐘"]
var cp = ord(c)
cps.append(cp)
writeLine(c + " = " + cp)
end
writeLine()
for each int i in cps
var c = chr(i)
writeLine(i + " = " + c)
end- Output:
97 a 960 π a = 97 π = 960 字 = 23383 🐘 = 128024 97 = a 960 = π 23383 = 字 128024 = 🐘
Erlang
In Erlang, lists and strings are the same, only the representation changes. Thus:
1> F = fun([X]) -> X end.
#Fun<erl_eval.6.13229925>
2> F("a").
97
If entered manually, one can also get ASCII codes by prefixing characters with $:
3> $a.
97
Unicode is fully supported since release R13A only.
Euphoria
printf(1,"%d\n", 'a') -- prints "97"
printf(1,"%s\n", 97) -- prints "a"F#
let c = 'A'
let n = 65
printfn "%d" (int c)
printfn "%c" (char n)
- Output:
65 A
Factor
CHAR: katakana-letter-a .
"ア" first .
12450 1string print
FALSE
'A."
"65,Fantom
A character is represented in single quotes: the 'toInt' method returns the code for the character. The 'toChar' method converts an integer into its respective character.
fansh> 97.toChar
a
fansh> 'a'.toInt
97Fennel
(string.byte :A) ; 65
(string.char 65) ; "A"
Forth
As with C, characters are just integers on the stack which are treated as ASCII.
char a
dup . \ 97
emit \ a
Fortran
Functions ACHAR and IACHAR specifically work with the ASCII character set, while the results of CHAR and ICHAR will depend on the default character set being used.
WRITE(*,*) ACHAR(97), IACHAR("a")
WRITE(*,*) CHAR(97), ICHAR("a")
Free Pascal
See Pascal
FreeBASIC
' FreeBASIC v1.05.0 win64
Print "a - > "; Asc("a")
Print "98 -> "; Chr(98)
Print
Print "Press any key to exit the program"
Sleep
End- Output:
a - > 97 98 -> b
Frink
The function char[x] in Frink returns the numerical Unicode codepoints for a string or character, or returns the Unicode string for an integer value or array of integer values. The chars[x] returns an array even if the string is a single character. These functions also correctly handle upper-plane Unicode characters as a single codepoint.
println[char["a"]] // prints 97
println[chars["a"]] // prints [97] (an array)
println[char[97]] // prints a
println[char["Frink rules!"]] // prints [70, 114, 105, 110, 107, 32, 114, 117, 108, 101, 115, 33]
println[[70, 114, 105, 110, 107, 32, 114, 117, 108, 101, 115, 33]] // prints "Frink rules!"
FutureBasic
print "a -> "; ASC("a")
print "98 -> "; CHR$(98)
handleevents- Output:
a -> 97 98 -> b
Gambas
Public Sub Form_Open()
Dim sChar As String
sChar = InputBox("Enter a character")
Print "Character " & sChar & " = ASCII " & Str(Asc(sChar))
sChar = InputBox("Enter a ASCII code")
Print "ASCII code " & sChar & " represents " & Chr(Val(sChar))
EndOutput:
Character W = ASCII 87 ASCII code 35 represents #
GAP==
# Code must be in 0 .. 255.
CharInt(65);
# 'A'
IntChar('Z');
# 90
Go
In Go, a character literal is simply an integer constant of the character code:
fmt.Println('a') // prints "97"
fmt.Println('π') // prints "960"
package main
import (
"fmt"
)
func main() {
// Given a character value in your language, print its code
fmt.Printf("%d\n", 'A') // prt 65
// Given a code, print out the corresponding character.
fmt.Printf("%c\n", 65) // prt A
}
Literal constants in Go are not typed (named constants can be).
The variable and constant types most commonly used for character data are byte, rune, and string.
This example program shows character codes (as literals) stored in typed variables, and printed out with default formatting. Note that since byte and rune are integer types, the default formatting is a printable base 10 number. String is not numeric, and a little extra work must be done to print the character codes.
package main
import "fmt"
func main() {
// yes, there is more concise syntax, but this makes
// the data types very clear.
var b byte = 'a'
var r rune = 'π'
var s string = "aπ"
fmt.Println(b, r, s)
fmt.Println("string cast to []rune:", []rune(s))
// A range loop over a string gives runes, not bytes
fmt.Print(" string range loop: ")
for _, c := range s {
fmt.Print(c, " ") // c is type rune
}
// We can also print the bytes of a string without an explicit loop
fmt.Printf("\n string bytes: % #x\n", s)
}
- Output:
97 960 aπ
string cast to []rune: [97 960]
string range loop: 97 960
string bytes: 0x61 0xcf 0x80
For the second part of the task, printing the character of a given code, the %c verb of fmt.Printf will do this directly from integer values, emitting the UTF-8 encoding of the code, (which will typically print the character depending on your hardware and operating system configuration).
b := byte(97)
r := rune(960)
fmt.Printf("%c %c\n%c %c\n", 97, 960, b, r)
- Output:
a π a π
You can think of the default formatting of strings as being the printable characters of the string. In fact however, it is even simpler. Since we expect our output device to interpret UTF-8, and we expect our string to contain UTF-8, the default formatting simply dumps the bytes of the string to the output.
Examples showing strings constructed from integer constants and then printed:
fmt.Println(string(97)) // prints "a"
fmt.Println(string(960)) // prints "π"
fmt.Println(string([]rune{97, 960})) // prints "aπ"
Golfscript
To convert a number to a string, we use the array to string coercion.
97[]+''+pTo convert a string to a number, we have a many options, of which the simplest and shortest are:
'a')\;p
'a'(\;p
'a'0=p
'a'{}/pGroovy
Groovy does not have a character literal at all, so one-character strings have to be coerced to char. Groovy printf (like Java, but unlike C) is not type-agnostic, so the cast or coercion from char to int is also required. The reverse direction is considerably simpler.
printf ("%d\n", ('a' as char) as int)
printf ("%c\n", 97)
- Output:
97 a
Haskell
import Data.Char
main = do
print (ord 'a') -- prints "97"
print (chr 97) -- prints "'a'"
print (ord 'π') -- prints "960"
print (chr 960) -- prints "'\960'"
HicEst
WRITE(Messagebox) ICHAR('a'), CHAR(97)HolyC
Print("%d\n", 'a'); /* prints "97" */
Print("%c\n", 97); /* prints "a" */Hoon
|%
++ enc
|= char=@t `@ud`char
++ dec
|= code=@ud `@t`code
--i
software {
print(number('a'))
print(text([97]))
}Icon and Unicon
Icon and Unicon do not currently support double byte character sets.
- Output:
97 ==> a a ==> 97
Io
Here character is a sequence (string) of length one.
"a" at(0) println // --> 97
97 asCharacter println // --> a
"π" at(0) println // --> 960
960 asCharacter println // --> π
J
4 u: 97 98 99 9786
abc☺
3 u: 7 u: 'abc☺'
97 98 99 9786
7 u: converts to utf-16 (8 u: would convert to utf-8, and 9 u: would convert to utf-32), and 3 u: converts what the uncode consortium calls "code points" to numeric form. Since J character literals are utf-8 (primarily because that's how OS interfaces work), by itself 3 u: would give us:
3 u: 'abc☺'
97 98 99 226 152 186
Also, if we limit ourselves to ascii, we have other ways of accomplishing the same thing. a. is a list of the 8 bit character codes and we can index from it, or search it (though that's mostly a notational convenience, since the underlying type already gives us all we need to know).
97 98 99{a.
abc
a.i.'abc'
97 98 99
Java
In Java, a char is a 2-byte unsigned value, so it will fit within an 4-byte int.
To convert a character to it's ASCII code, cast the char to an int.
The following will yield 97.
(int) 'a'
You could also specify a unicode hexadecimal value, using the \u escape sequence.
(int) '\u0061'
To convert an ASCII code to it's ASCII representation, cast the int value to a char.
(char) 97
Java also offers the Character class, comprised of several utilities for Unicode based operations.
Here are a few examples.
Get the integer value represented by the ASCII character.
The second parameter here, is the radix.
This will return an int with the value of 1.
Character.digit('1', 10)
Inversely, get the ASCII representation of the integer.
Again, the second parameter is the radix.
This will return a char with the value of '1'.
Character.forDigit(1, 10)
JavaScript
Here character is just a string of length 1
console.log('a'.charCodeAt(0)); // prints "97"
console.log(String.fromCharCode(97)); // prints "a"
ES6 brings String.codePointAt() and String.fromCodePoint(), which provide access to 4-byte unicode characters, in addition to the usual 2-byte unicode characters.
['字'.codePointAt(0), '🐘'.codePointAt(0)]
- Output:
[23383, 128024]
and
[23383, 128024].map(function (x) {
return String.fromCodePoint(x);
})
- Output:
["字", "🐘"]
Joy
'a ord.
97 chr.jq
jq data strings are JSON strings, which can be "explode"d into an array of integers, each representing a Unicode codepoint. The inverse of the explode filter is implode. explode can of course be used for single-character strings, and so for example:
"a" | explode # => [ 97 ]
[97] | implode # => "a"Here is a filter which can be used to convert an integer to the corresponding
character:
def chr: [.] | implode;Example: 1024 | chr # => "Ѐ"
Julia
Julia character constants (of type Char) are treated as an integer type representing the Unicode codepoint of the character, and can easily be converted to and from other integer types.
println(Int('a'))
println(Char(97))
- Output:
97 a
K
_ic "abcABC"
97 98 99 65 66 67
_ci 97 98 99 65 66 67
"abcABC"
Kotlin
fun main() {
var c = 'a'
var i = c.code
println("$c <-> $i")
i += 2
c = i.toChar()
println("$i <-> $c")
}
- Output:
a <-> 97 99 <-> c
LabVIEW
This image is a VI Snippet, an executable image of LabVIEW code. The LabVIEW version is shown on the top-right hand corner. You can download it, then drag-and-drop it onto the LabVIEW block diagram from a file browser, and it will appear as runnable, editable code.

Lang
fn.println(fn.toValue(a)) # Prints "97"
fn.println(fn.toChar(97)) # Prints "a"
# Unicode
fn.println(fn.toValue(π)) # Prints "960"
fn.println(fn.toChar(960)) # Prints "π"Lang5
: CHAR "!\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[" comb
'\\ comb -1 remove append "]^_`abcdefghijklmnopqrstuvwxyz{|}~" comb append ;
: CODE 95 iota 33 + ; : comb "" split ;
: extract' rot 1 compress index subscript expand drop ;
: chr CHAR CODE extract' ;
: ord CODE CHAR extract' ;
'a ord . # 97
97 chr . # alangur
Langur has code point literals (enclosed in straight single quotes), which may use escape codes. They are integers.
The s2cp(), cp2s(), and s2gc() functions convert between code point integers, grapheme clusters and strings. Also, string indexing is by code point.
val .a1 = 'a'
val .a2 = 97
val .a3 = "a"[1]
val .a4 = s2cp "a", 1
val .a5 = [.a1, .a2, .a3, .a4]
writeln .a1 == .a2
writeln .a2 == .a3
writeln .a3 == .a4
writeln "numbers: ", join ", ", [.a1, .a2, .a3, .a4, .a5]
writeln "letters: ", join ", ", map cp2s, [.a1, .a2, .a3, .a4, .a5]- Output:
true true true numbers: 97, 97, 97, 97, [97, 97, 97, 97] letters: a, a, a, a, aaaa
Lasso
'a'->integer
'A'->integer
97->bytes
65->bytes
- Output:
9765 a
A
LFE
In LFE/Erlang, lists and strings are the same, only the representation changes. For example:
> (list 68 111 110 39 116 32 80 97 110 105 99 46)
"Don't Panic."
As for this exercise, here's how you could print out the ASCII code for a letter, and a letter from the ASCII code:
> (: io format '"~w~n" '"a")
97
ok
> (: io format '"~p~n" (list '(97)))
"a"
ok
Liberty BASIC
charCode = 97
char$ = "a"
print chr$(charCode) 'prints a
print asc(char$) 'prints 97LIL
LIL does not handle NUL bytes in character strings, char 0 returns an empty string.
print [char 97]
print [codeat "a" 0]
- Output:
a 97
Lingo
-- returns Unicode code point (=ASCII code for ASCII characters) for character
put chartonum("a")
-- 97
-- returns character for Unicode code point (=ASCII code for ASCII characters)
put numtochar(934)
-- ΦLittle
puts("Unicode value of ñ is ${scan("ñ", "%c")}");
printf("The code 241 in Unicode is the letter: %c.\n", 241);
LiveCode
Since 7.0.x works with unicode
put charToNum("") && numToChar(240)Logo
Logo characters are words of length 1.
print ascii "a ; 97
print char 97 ; aLogtalk
|?- char_code(Char, 97), write(Char).
a
Char = a
yes
|?- char_code(a, Code), write(Code).
97
Code = 97
yes
Lua
print(string.byte("a")) -- prints "97"
print(string.char(97)) -- prints "a"
M2000 Interpreter
\\ ANSI
Print Asc("a")
Print Chr$(Asc("a"))
\\ Utf16-Le
Print ChrCode("a")
Print ChrCode$(ChrCode("a"))
\\ (,) is an empty array.
Function Codes(a$) {
If Len(A$)=0 then =(,) : Exit
Buffer Mem as byte*Len(a$)
\\ Str$(string) return one byte character
Return Mem, 0:=Str$(a$)
Inventory Codes
For i=0 to len(Mem)-1
Append Codes, i:=Eval(Mem, i)
Next i
=Codes
}
Print Codes("abcd")
\\ 97 98 99 100Maple
There are two ways to do this in Maple. First, there are procedures in StringTools for this purpose.
> use StringTools in Ord( "A" ); Char( 65 ) end;
65
"A"Second, the procedure convert handles conversions to and from byte values.
> convert( "A", bytes );
[65]
> convert( [65], bytes );
"A"Mathematica / Wolfram Language
Use the FromCharacterCode and ToCharacterCode functions:
ToCharacterCode["abcd"]
FromCharacterCode[{97}]
- Output:
{97, 98, 99, 100}
"a"
MATLAB / Octave
There are two built-in function that perform these tasks. To convert from a number to a character use:
character = char(asciiNumber)
To convert from a character to its corresponding ascii character use:
asciiNumber = double(character)
or if you need this number as an integer not a double use:
asciiNumber = uint16(character)
asciiNumber = uint32(character)
asciiNumber = uint64(character)
Sample Usage:
>> char(87)
ans =
W
>> double('W')
ans =
87
>> uint16('W')
ans =
87
Maxima
ascii(65);
"A"
cint("A");
65
Metafont
Metafont handles only ASCII (even though codes beyond 127 can be given and used as real ASCII codes)
message "enter a letter: ";
string a;
a := readstring;
message decimal (ASCII a); % writes the decimal number of the first character
% of the string a
message "enter a number: ";
num := scantokens readstring;
message char num; % num can be anything between 0 and 255; what will be seen
% on output depends on the encoding used by the "terminal"; e.g.
% any code beyond 127 when UTF-8 encoding is in use will give
% a bad encoding; e.g. to see correctly an "è", we should write
message char10; % (this add a newline...)
message char hex"c3" & char hex"a8"; % since C3 A8 is the UTF-8 encoding for "è"
endMicrosoft Small Basic
TextWindow.WriteLine("The ascii code for 'A' is: " + Text.GetCharacterCode("A") + ".")
TextWindow.WriteLine("The character for '65' is: " + Text.GetCharacter(65) + ".")- Output:
The ascii code for 'A' is: 65.
The character for '65' is: A.
Press any key to continue...
MiniScript
MiniScript does not have a character type as such but one can use single character strings instead. Strings can contain any Unicode code point.
cps = []
for c in ["a", "π", "字", "🐘"]
cp = c.code
cps.push cp
print c + " = " + cp
end for
print
for i in cps
print i + " = " + char(i)
end for
- Output:
a = 97 π = 960 字 = 23383 🐘 = 128024 97 = a 960 = π 23383 = 字 128024 = 🐘
Modula-2
MODULE asc;
IMPORT InOut;
VAR letter : CHAR;
ascii : CARDINAL;
BEGIN
letter := 'a';
InOut.Write (letter);
ascii := ORD (letter);
InOut.Write (11C); (* ASCII TAB *)
InOut.WriteCard (ascii, 8);
ascii := ascii - ORD ('0');
InOut.Write (11C); (* ASCII TAB *)
InOut.Write (CHR (ascii));
InOut.WriteLn
END asc.
- Output:
jan@Beryllium:~/modula/rosetta$ ./asc
a 97 1Modula-3
The built in functions ORD and VAL work on characters, among other things.
ORD('a') (* Returns 97 *)
VAL(97, CHAR); (* Returns 'a' *)MUMPS
WRITE $ASCII("M")
WRITE $CHAR(77)Nanoquery
println ord("a")
println chr(97)
println ord("π")
println chr(960)- Output:
97 a 960 π
Neko
Neko treats strings as an array of bytes
// An 'a' and a 'b'
var s = "a";
var c = 98;
var h = " ";
$print("Character code for 'a': ", $sget(s, 0), "\n");
$sset(h, 0, c);
$print("Character code ", c, ": ", h, "\n");- Output:
Character code for 'a': 97 Character code 98: b
Neko also has standard primitives for handling the byte array as UTF-8
// While Neko also includes some UTF-8 operations,
// native strings are just arrays of bytes
var us = "¥·£·€·$·¢·₡·₢·₣·₤·₥·₦·₧·₨·₩·₪·₫·₭·₮·₯·₹";
// load some Std lib primitives
utfGet = $loader.loadprim("std@utf8_get", 2);
utfSub = $loader.loadprim("std@utf8_sub", 3);
utfAlloc = $loader.loadprim("std@utf8_buf_alloc", 1);
utfAdd = $loader.loadprim("std@utf8_buf_add", 2);
utfContent = $loader.loadprim("std@utf8_buf_content", 1);
// Pull out the Euro currency symbol from the UTF-8 currency sampler
var uc = utfGet(us, 4);
$print("UFT-8 code for '", utfSub(us, 4, 1), "': ", uc, "\n");
// Build a UTF-8 buffer
var buf = utfAlloc(4);
// Add a Pound Sterling symbol
uc = 8356;
utfAdd(buf, uc);
$print("UTF-8 code ", uc, ": ", utfContent(buf), "\n");- Output:
UFT-8 code for '€': 8364 UTF-8 code 8356: ₤
NESL
In NESL, character literals are prefixed with a backtick. The functions char_code and code_char convert between characters and integer character codes.
char_code(`a);
it = 97 : intcode_char(97);
it = `a : charNetRexx
NetRexx provides built-in functions to convert between character and decimal/hexadecimal.
/* NetRexx */
options replace format comments java crossref symbols nobinary
runSample(arg)
return
-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
method runSample(arg) private static
-- create some sample data: character, hex and unicode
samp = ' ' || 'a'.sequence('e') || '$' || '\xa2'.sequence('\xa5') || '\u20a0'.sequence('\u20b5')
-- use the C2D C2X D2C and X2C built-in functions
say "'"samp"'"
say ' | Chr C2D C2X D2C X2C'
say '---+ --- ------ ---- --- ---'
loop ci = 1 to samp.length
cc = samp.substr(ci, 1)
cd = cc.c2d -- char to decimal
cx = cc.c2x -- char to hexadecimal
dc = cd.d2c -- decimal to char
xc = cx.x2c -- hexadecimal to char
say ci.right(3)"| '"cc"'" cd.right(6) cx.right(4, 0) "'"dc"' '"xc"'"
end ci
return- Output:
' abcde$¢£¤¥₠₡₢₣₤₥₦₧₨₩₪₫€₭₮₯₰₱₲₳₴₵' | Chr C2D C2X D2C X2C ---+ --- ------ ---- --- --- 1| ' ' 32 0020 ' ' ' ' 2| 'a' 97 0061 'a' 'a' 3| 'b' 98 0062 'b' 'b' 4| 'c' 99 0063 'c' 'c' 5| 'd' 100 0064 'd' 'd' 6| 'e' 101 0065 'e' 'e' 7| '$' 36 0024 '$' '$' 8| '¢' 162 00A2 '¢' '¢' 9| '£' 163 00A3 '£' '£' 10| '¤' 164 00A4 '¤' '¤' 11| '¥' 165 00A5 '¥' '¥' 12| '₠' 8352 20A0 '₠' '₠' 13| '₡' 8353 20A1 '₡' '₡' 14| '₢' 8354 20A2 '₢' '₢' 15| '₣' 8355 20A3 '₣' '₣' 16| '₤' 8356 20A4 '₤' '₤' 17| '₥' 8357 20A5 '₥' '₥' 18| '₦' 8358 20A6 '₦' '₦' 19| '₧' 8359 20A7 '₧' '₧' 20| '₨' 8360 20A8 '₨' '₨' 21| '₩' 8361 20A9 '₩' '₩' 22| '₪' 8362 20AA '₪' '₪' 23| '₫' 8363 20AB '₫' '₫' 24| '€' 8364 20AC '€' '€' 25| '₭' 8365 20AD '₭' '₭' 26| '₮' 8366 20AE '₮' '₮' 27| '₯' 8367 20AF '₯' '₯' 28| '₰' 8368 20B0 '₰' '₰' 29| '₱' 8369 20B1 '₱' '₱' 30| '₲' 8370 20B2 '₲' '₲' 31| '₳' 8371 20B3 '₳' '₳' 32| '₴' 8372 20B4 '₴' '₴' 33| '₵' 8373 20B5 '₵' '₵'
Nim
echo ord('a') # echoes 97
echo chr(97) # echoes a
import unicode
echo int("π".runeAt(0)) # echoes 960
echo Rune(960) # echoes π
NS-HUBASIC
NS-HUBASIC uses a non-ASCII character set that doesn't include letters in lowercase.
10 PRINT CODE "A"
20 PRINT CHR$(38)- Output:
0A &
Oberon-2
MODULE Ascii;
IMPORT Out;
VAR
c: CHAR;
d: INTEGER;
BEGIN
c := CHR(97);
d := ORD("a");
Out.Int(d,3);Out.Ln;
Out.Char(c);Out.Ln
END Ascii.- Output:
97
a
Objeck
'a'->As(Int)->PrintLine();
97->As(Char)->PrintLine();Object Pascal
See Pascal
OCaml
Printf.printf "%d\n" (int_of_char 'a'); (* prints "97" *)
Printf.printf "%c\n" (char_of_int 97); (* prints "a" *)
The following are aliases for the above functions:
# Char.code ;;
- : char -> int = <fun>
# Char.chr;;
- : int -> char = <fun>
Oforth
Oforth has not type or class for characters. A character is an integer which value is its unicode code.
'a' println- Output:
97
OpenEdge/Progress
MESSAGE
CHR(97) SKIP
ASC("a")
VIEW-AS ALERT-BOX.Oz
Characters in Oz are the same as integers in the range 0-255 (ISO 8859-1 encoding). To print a number as a character, we need to use it as a string (i.e. a list of integers from 0 to 255):
{System.show &a} %% prints "97"
{System.showInfo [97]} %% prints "a"PARI/GP
print(Vecsmall("a")[1]);
print(Strchr([72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 33]))Pascal
writeln(ord('a'));
writeln(chr(97));
Plain English
\ Obs: The little-a byte is a byte equal to 97.
Write the little-a byte's whereabouts on the console.
Put 97 into a number.
Write the number's target on the console.Perl
Narrow
The code is straightforward when characters are all narrow (single byte).
use strict;
use warnings;
use utf8;
binmode(STDOUT, ':utf8');
use Encode;
use Unicode::UCD 'charinfo';
use List::AllUtils qw(zip natatime);
for my $c (split //, 'AΑА薵') {
my $o = ord $c;
my $utf8 = join '', map { sprintf "%x ", ord } split //, Encode::encode("utf8", $c);
my $iterator = natatime 2, zip
@{['Character', 'Character name', 'Ordinal(s)', 'Hex ordinal(s)', 'UTF-8', 'Round trip']},
@{[ $c, charinfo($o)->{'name'}, $o, sprintf("0x%x",$o), $utf8, chr $o, ]};
while ( my ($label, $value) = $iterator->() ) {
printf "%14s: %s\n", $label, $value
}
print "\n";
}
- Output:
Character: A
Character name: LATIN CAPITAL LETTER A
Ordinal(s): 65
Hex ordinal(s): 0x41
UTF-8: 41
Round trip: A
Character: Α
Character name: GREEK CAPITAL LETTER ALPHA
Ordinal(s): 913
Hex ordinal(s): 0x391
UTF-8: ce 91
Round trip: Α
Character: А
Character name: CYRILLIC CAPITAL LETTER A
Ordinal(s): 1040
Hex ordinal(s): 0x410
UTF-8: d0 90
Round trip: А
Character: 薵
Character name: CJK UNIFIED IDEOGRAPH-2A6A5
Ordinal(s): 173733
Hex ordinal(s): 0x2a6a5
UTF-8: f0 aa 9a a5
Round trip: 薵
Wide
Have to work a little harder to handle wide (multi-byte) characters.
use strict;
use warnings;
use feature 'say';
use utf8;
binmode(STDOUT, ':utf8');
use Unicode::Normalize 'NFC';
use Unicode::UCD qw(charinfo charprop);
while ('Δ̂🇺🇸👨👩👧👦' =~ /(\X)/g) {
my @ordinals = map { ord } split //, my $c = $1;
printf "%14s: %s\n"x7 . "\n",
'Character', NFC $c,
'Character name', join(', ', map { charinfo($_)->{'name'} } @ordinals),
'Unicode property', join(', ', map { charprop($_, "Gc") } @ordinals),
'Ordinal(s)', join(' ', @ordinals),
'Hex ordinal(s)', join(' ', map { sprintf("0x%x", $_) } @ordinals),
'UTF-8', join('', map { sprintf "%x ", ord } (utf8::encode($c), split //, $c)),
'Round trip', join('', map { chr } @ordinals);
}
- Output:
Character: Δ̂
Character name: GREEK CAPITAL LETTER DELTA, COMBINING CIRCUMFLEX ACCENT
Unicode property: Uppercase_Letter, Nonspacing_Mark
Ordinal(s): 916 770
Hex ordinal(s): 0x394 0x302
UTF-8: ce 94 cc 82
Round trip: Δ̂
Character: 🇺🇸
Character name: REGIONAL INDICATOR SYMBOL LETTER U, REGIONAL INDICATOR SYMBOL LETTER S
Unicode property: Other_Symbol, Other_Symbol
Ordinal(s): 127482 127480
Hex ordinal(s): 0x1f1fa 0x1f1f8
UTF-8: f0 9f 87 ba f0 9f 87 b8
Round trip: 🇺🇸
Character: 👨👩👧👦
Character name: MAN, ZERO WIDTH JOINER, WOMAN, ZERO WIDTH JOINER, GIRL, ZERO WIDTH JOINER, BOY
Unicode property: Other_Symbol, Format, Other_Symbol, Format, Other_Symbol, Format, Other_Symbol
Ordinal(s): 128104 8205 128105 8205 128103 8205 128102
Hex ordinal(s): 0x1f468 0x200d 0x1f469 0x200d 0x1f467 0x200d 0x1f466
UTF-8: f0 9f 91 a8 e2 80 8d f0 9f 91 a9 e2 80 8d f0 9f 91 a7 e2 80 8d f0 9f 91 a6
Round trip: 👨👩👧👦
Phix
Characters and their ascii codes are one and the same. (See also printf, %d / %s / %c.)
?'A' puts(1,65)
- Output:
65 A
Phixmonti
'a' print nl
97 tochar printPHP
Here character is just a string of length 1
echo ord('a'), "\n"; // prints "97"
echo chr(97), "\n"; // prints "a"
Picat
main =>
println(chr(97)),
println(ord('a')),
println(ord(a)).- Output:
a 97 97
PicoLisp
: (char "a")
-> 97
: (char "字")
-> 23383
: (char 23383)
-> "字"
: (chop "文字")
-> ("文" "字")
: (mapcar char @)
-> (25991 23383)PL/I
declare 1 u union,
2 c character (1),
2 i fixed binary (8) unsigned;
c = 'a'; put skip list (i); /* prints 97 */
i = 97; put skip list (c); /* prints 'a' */PowerShell
Powershell does allow for character literals with [convert]
$char = [convert]::toChar(0x2f) #=> /
PowerShell does not allow for character literals directly, so to get a character one first needs to convert a single-character string to a char:
$char = [char] 'a'
Then a simple cast to int yields the character code:
$charcode = [int] $char # => 97This also works with Unicode:
[int] [char] '☺' # => 9786For converting an integral character code into the actual character, a cast to char suffices:
[char] 97 # a
[char] 9786 # ☺Prolog
SWI-Prolog has predefined predicate char_code/2.
?- char_code(a, X). X = 97. ?- char_code(X, 97). X = a.
PureBasic
PureBasic allows compiling code so that it will use either Ascii or a Unicode (UCS-2) encoding for representing its string content. It also allows for the source code that is being compiled to be in either Ascii or UTF-8 encoding. A one-character string is used here to hold the character and a numerical character type is used to hold the character code. The character type is either one or two bytes in size, depending on whether compiling for Ascii or Unicode respectively.
If OpenConsole()
;Results are the same when compiled for Ascii or Unicode
charCode.c = 97
Char.s = "a"
PrintN(Chr(charCode)) ;prints a
PrintN(Str(Asc(Char))) ;prints 97
Print(#CRLF$ + #CRLF$ + "Press ENTER to exit")
Input()
CloseConsole()
EndIfThis version should be compiled with Unicode setting and the source code to be encoded using UTF-8.
If OpenConsole()
;UTF-8 encoding compiled for Unicode (UCS-2)
charCode.c = 960
Char.s = "π"
PrintN(Chr(charCode)) ;prints π
PrintN(Str(Asc(Char))) ;prints 960
Print(#CRLF$ + #CRLF$ + "Press ENTER to exit")
Input()
CloseConsole()
EndIfPython
Here character is just a string of length 1
8-bit characters:
print ord('a') # prints "97"
print chr(97) # prints "a"Unicode characters:
print ord(u'π') # prints "960"
print unichr(960) # prints "π"Here character is just a string of length 1
print(ord('a')) # prints "97" (will also work in 2.x)
print(ord('π')) # prints "960"
print(chr(97)) # prints "a" (will also work in 2.x)
print(chr(960)) # prints "π"Quackery
As a dialogue in the Quackery shell.
Welcome to Quackery. Enter "leave" to leave the shell. /O> char a ... Stack: 97 /O> emit ... a Stack empty.
R
ascii <- as.integer(charToRaw("hello world")); ascii
text <- rawToChar(as.raw(ascii)); textRacket
#lang racket
(define (code ch)
(printf "The unicode number for ~s is ~a\n" ch (char->integer ch)))
(code #\a)
(code #\λ)
(define (char n)
(printf "The unicode number ~a is the character ~s\n" n (integer->char n)))
(char 97)
(char 955)Raku
(formerly Perl 6) Both Perl 5 and Raku have good Unicode support, though Raku attempts to make working with Unicode effortless. Note that even multi-byte emoji and characters outside the BMP are considered single characters. Also note: all of these routines are built into the base compiler. No need to load external libraries. See Wikipedia: Unicode character properties for explanation of Unicode property.
for 'AΑА𪚥🇺🇸👨👩👧👦'.comb {
.put for
[ 'Character',
'Character name',
'Unicode property',
'Unicode script',
'Unicode block',
'Added in Unicode version',
'Ordinal(s)',
'Hex ordinal(s)',
'UTF-8',
'UTF-16LE',
'UTF-16BE',
'Round trip by name',
'Round trip by ordinal'
]».fmt('%25s:')
Z
[ $_,
.uninames.join(', '),
.uniprops.join(', '),
.uniprops('Script').join(', '),
.uniprops('Block').join(', '),
.uniprops('Age').join(', '),
.ords,
.ords.fmt('0x%X'),
.encode('utf8' )».fmt('%02X'),
.encode('utf16le')».fmt('%02X').join.comb(4),
.encode('utf16be')».fmt('%02X').join.comb(4),
.uninames».uniparse.join,
.ords.chrs
];
say '';
}- Output:
Character: A
Character name: LATIN CAPITAL LETTER A
Unicode property: Lu
Unicode script: Latin
Unicode block: Basic Latin
Added in Unicode version: 1.1
Ordinal(s): 65
Hex ordinal(s): 0x41
UTF-8: 41
UTF-16LE: 4100
UTF-16BE: 0041
Round trip by name: A
Round trip by ordinal: A
Character: Α
Character name: GREEK CAPITAL LETTER ALPHA
Unicode property: Lu
Unicode script: Greek
Unicode block: Greek and Coptic
Added in Unicode version: 1.1
Ordinal(s): 913
Hex ordinal(s): 0x391
UTF-8: CE 91
UTF-16LE: 9103
UTF-16BE: 0391
Round trip by name: Α
Round trip by ordinal: Α
Character: А
Character name: CYRILLIC CAPITAL LETTER A
Unicode property: Lu
Unicode script: Cyrillic
Unicode block: Cyrillic
Added in Unicode version: 1.1
Ordinal(s): 1040
Hex ordinal(s): 0x410
UTF-8: D0 90
UTF-16LE: 1004
UTF-16BE: 0410
Round trip by name: А
Round trip by ordinal: А
Character: 𪚥
Character name: CJK UNIFIED IDEOGRAPH-2A6A5
Unicode property: Lo
Unicode script: Han
Unicode block: CJK Unified Ideographs Extension B
Added in Unicode version: 3.1
Ordinal(s): 173733
Hex ordinal(s): 0x2A6A5
UTF-8: F0 AA 9A A5
UTF-16LE: 69D8 A5DE
UTF-16BE: D869 DEA5
Round trip by name: 𪚥
Round trip by ordinal: 𪚥
Character: 🇺🇸
Character name: REGIONAL INDICATOR SYMBOL LETTER U, REGIONAL INDICATOR SYMBOL LETTER S
Unicode property: So, So
Unicode script: Common, Common
Unicode block: Enclosed Alphanumeric Supplement, Enclosed Alphanumeric Supplement
Added in Unicode version: 6.0, 6.0
Ordinal(s): 127482 127480
Hex ordinal(s): 0x1F1FA 0x1F1F8
UTF-8: F0 9F 87 BA F0 9F 87 B8
UTF-16LE: 3CD8 FADD 3CD8 F8DD
UTF-16BE: D83C DDFA D83C DDF8
Round trip by name: 🇺🇸
Round trip by ordinal: 🇺🇸
Character: 👨👩👧👦
Character name: MAN, ZERO WIDTH JOINER, WOMAN, ZERO WIDTH JOINER, GIRL, ZERO WIDTH JOINER, BOY
Unicode property: So, Cf, So, Cf, So, Cf, So
Unicode script: Common, Inherited, Common, Inherited, Common, Inherited, Common
Unicode block: Miscellaneous Symbols and Pictographs, General Punctuation, Miscellaneous Symbols and Pictographs, General Punctuation, Miscellaneous Symbols and Pictographs, General Punctuation, Miscellaneous Symbols and Pictographs
Added in Unicode version: 6.0, 1.1, 6.0, 1.1, 6.0, 1.1, 6.0
Ordinal(s): 128104 8205 128105 8205 128103 8205 128102
Hex ordinal(s): 0x1F468 0x200D 0x1F469 0x200D 0x1F467 0x200D 0x1F466
UTF-8: F0 9F 91 A8 E2 80 8D F0 9F 91 A9 E2 80 8D F0 9F 91 A7 E2 80 8D F0 9F 91 A6
UTF-16LE: 3DD8 68DC 0D20 3DD8 69DC 0D20 3DD8 67DC 0D20 3DD8 66DC
UTF-16BE: D83D DC68 200D D83D DC69 200D D83D DC67 200D D83D DC66
Round trip by name: 👨👩👧👦
Round trip by ordinal: 👨👩👧👦
RapidQ
Print Chr$(97)
Print Asc("a")Red
Red []
print to-integer first "a" ;; -> 97
print to-integer #"a" ;; -> 97
print to-binary "a" ;; -> #{61}
print to-char 97 ;; -> aRetro
'c putcREXX
REXX supports handling of characters with built-in functions (BIFs), whether it be hexadecimal, binary (bits), or decimal code(s).
ASCII
/*REXX program displays a char's ASCII code/value (or EBCDIC if run on an EBCDIC system)*/
yyy= 'c' /*assign a lowercase c to YYY. */
yyy= "c" /* (same as above) */
say 'from char, yyy code=' yyy
yyy= '63'x /*assign hexadecimal 63 to YYY. */
yyy= '63'X /* (same as above) */
say 'from hex, yyy code=' yyy
yyy= x2c(63) /*assign hexadecimal 63 to YYY. */
say 'from hex, yyy code=' yyy
yyy= '01100011'b /*assign a binary 0011 0100 to YYY. */
yyy= '0110 0011'b /* (same as above) */
yyy= '0110 0011'B /* " " " */
say 'from bin, yyy code=' yyy
yyy= d2c(99) /*assign decimal code 99 to YYY. */
say 'from dec, yyy code=' yyy
say /* [↓] displays the value of YYY in ··· */
say 'char code: ' yyy /* character code (as an 8-bit ASCII character).*/
say ' hex code: ' c2x(yyy) /* hexadecimal */
say ' dec code: ' c2d(yyy) /* decimal */
say ' bin code: ' x2b( c2x(yyy) ) /* binary (as a bit string) */
/*stick a fork in it, we're all done with display*/output
from char, yyy code= c from hex, yyy code= c from hex, yyy code= c from bin, yyy code= c from dec, yyy code= c char code: c hex code: 63 dec code: 99 bin code: 01100011
EBCDIC
/* REXX */
yyy='c' /*assign a lowercase c to YYY */
yyy='83'x /*assign hexadecimal 83 to YYY */
/*the X can be upper/lowercase.*/
yyy=x2c(83) /* (same as above) */
yyy='10000011'b /* (same as above) */
yyy='1000 0011'b /* (same as above) */
/*the B can be upper/lowercase.*/
yyy=d2c(129) /*assign decimal code 129 to YYY */
say yyy /*displays the value of YYY */
say c2x(yyy) /*displays the value of YYY in hexadecimal. */
say c2d(yyy) /*displays the value of YYY in decimal. */
say x2b(c2x(yyy))/*displays the value of YYY in binary (bit string). */- Output:
a 81 129 10000001
Ring
see ascii("a") + nl
see char(97) + nlRPL
- Input:
"a" NUM 97 CHR
- Output:
2: 97 1: "a"
Ruby
In Ruby 1.9 characters are represented as length-1 strings; same as in Python. The previous "character literal" syntax ?a is now the same as "a". Subscripting a string also gives a length-1 string. There is now an "ord" method of strings to convert a character into its integer code.
> "a".ord
=> 97
> 97.chr
=> "a"Run BASIC
print chr$(97) 'prints a
print asc("a") 'prints 97Rust
use std::char::from_u32;
fn main() {
//ascii char
println!("{}", 'a' as u8);
println!("{}", 97 as char);
//unicode char
println!("{}", 'π' as u32);
println!("{}", from_u32(960).unwrap());
}- Output:
97 a 960 π
Sather
class MAIN is
main is
#OUT + 'a'.int + "\n"; -- or
#OUT + 'a'.ascii_int + "\n";
#OUT + CHAR::from_ascii_int(97) + "\n";
end;
end;Scala
Scala supports unicode characters, but each character is UTF-16, so there is not a 1-to-1 relationship for supplementary character sets.
In a REPL session
scala> 'a' toInt
res2: Int = 97
scala> 97 toChar
res3: Char = a
scala> '\u0061'
res4: Char = a
scala> "\uD869\uDEA5"
res5: String = 𪚥Full swing workout
Taken the supplemental character sets in account.
import java.lang.Character._; import scala.annotation.tailrec
object CharacterCode extends App {
def intToChars(n: Int): Array[Char] = java.lang.Character.toChars(n)
def UnicodeToList(UTFstring: String) = {
@tailrec
def inner(str: List[Char], acc: List[String], surrogateHalf: Option[Char]): List[String] = {
(str, surrogateHalf) match {
case (Nil, _) => acc
case (ch :: rest, None) => if (ch.isSurrogate) inner(rest, acc, Some(ch))
else inner(rest, acc :+ ch.toString, None)
case (ch :: rest, Some(f)) => inner(rest, (acc :+ (f.toString + ch)), None)
}
}
inner(UTFstring.toList, Nil, None)
}
def UnicodeToInt(utf: String) = {
def charToInt(high: Char, low: Char) =
{ if (isSurrogatePair(high, low)) toCodePoint(high, low) else high.toInt }
charToInt(utf(0), if (utf.size > 1) utf(1) else 0)
}
def UTFtoHexString(utf: String) = { utf.map(ch => f"${ch.toInt}%04X").mkString("\"\\u", "\\u", "\"") }
def flags(ch: String) = { // Testing Unicode character properties
(if (ch matches "\\p{M}") "Y" else "N") + (if (ch matches "\\p{Mn}") "Y" else "N")
}
val str = '\uFEFF' /*big-endian BOM*/ + "\u0301a" +
"$áabcde¢£¤¥©ÇßIJijŁłʒλπक्तु•₠₡₢₣₤₥₦₧₨₩₪₫€₭₮₯₰₱₲₳₴₵℃←→⇒∙⌘☃☹☺☻ア字文𠀀" + intToChars(173733).mkString
println(s"Example string: $str")
println(""" | Chr C/C++/Java source Code Point Hex Dec Mn Name
!----+ --- ------------------------- ------- -------- -- """.stripMargin('!') + "-" * 27)
(UnicodeToList(str)).zipWithIndex.map {
case (coll, nr) =>
f"$nr%4d: $coll\t${UTFtoHexString(coll)}%27s U+${UnicodeToInt(coll)}%05X" +
f"${"(" + UnicodeToInt(coll).toString}%8s) ${flags(coll)} ${getName(coll(0).toInt)} "
}.foreach(println)
}- Output:
Example string: ́a$áabcde¢£¤¥©ÇßIJijŁłʒλπक्तु•₠₡₢₣₤₥₦₧₨₩₪₫€₭₮₯₰₱₲₳₴₵℃←→⇒∙⌘☃☹☺☻ア字文𠀀𪚥
| Chr C/C++/Java source Code Point Hex Dec Mn Name
----+ --- ------------------------- ------- -------- -- ---------------------------
0: "\uFEFF" U+0FEFF (65279) NN ZERO WIDTH NO-BREAK SPACE
1: ́ "\u0301" U+00301 (769) YY COMBINING ACUTE ACCENT
2: a "\u0061" U+00061 (97) NN LATIN SMALL LETTER A
3: $ "\u0024" U+00024 (36) NN DOLLAR SIGN
4: á "\u00E1" U+000E1 (225) NN LATIN SMALL LETTER A WITH ACUTE
5: a "\u0061" U+00061 (97) NN LATIN SMALL LETTER A
6: b "\u0062" U+00062 (98) NN LATIN SMALL LETTER B
7: c "\u0063" U+00063 (99) NN LATIN SMALL LETTER C
8: d "\u0064" U+00064 (100) NN LATIN SMALL LETTER D
9: e "\u0065" U+00065 (101) NN LATIN SMALL LETTER E
10: ¢ "\u00A2" U+000A2 (162) NN CENT SIGN
11: £ "\u00A3" U+000A3 (163) NN POUND SIGN
12: ¤ "\u00A4" U+000A4 (164) NN CURRENCY SIGN
13: ¥ "\u00A5" U+000A5 (165) NN YEN SIGN
14: © "\u00A9" U+000A9 (169) NN COPYRIGHT SIGN
15: Ç "\u00C7" U+000C7 (199) NN LATIN CAPITAL LETTER C WITH CEDILLA
16: ß "\u00DF" U+000DF (223) NN LATIN SMALL LETTER SHARP S
17: IJ "\u0132" U+00132 (306) NN LATIN CAPITAL LIGATURE IJ
18: ij "\u0133" U+00133 (307) NN LATIN SMALL LIGATURE IJ
19: Ł "\u0141" U+00141 (321) NN LATIN CAPITAL LETTER L WITH STROKE
20: ł "\u0142" U+00142 (322) NN LATIN SMALL LETTER L WITH STROKE
21: ʒ "\u0292" U+00292 (658) NN LATIN SMALL LETTER EZH
22: λ "\u03BB" U+003BB (955) NN GREEK SMALL LETTER LAMDA
23: π "\u03C0" U+003C0 (960) NN GREEK SMALL LETTER PI
24: क "\u0915" U+00915 (2325) NN DEVANAGARI LETTER KA
25: ् "\u094D" U+0094D (2381) YY DEVANAGARI SIGN VIRAMA
26: त "\u0924" U+00924 (2340) NN DEVANAGARI LETTER TA
27: ु "\u0941" U+00941 (2369) YY DEVANAGARI VOWEL SIGN U
28: • "\u2022" U+02022 (8226) NN BULLET
29: ₠ "\u20A0" U+020A0 (8352) NN EURO-CURRENCY SIGN
30: ₡ "\u20A1" U+020A1 (8353) NN COLON SIGN
31: ₢ "\u20A2" U+020A2 (8354) NN CRUZEIRO SIGN
32: ₣ "\u20A3" U+020A3 (8355) NN FRENCH FRANC SIGN
33: ₤ "\u20A4" U+020A4 (8356) NN LIRA SIGN
34: ₥ "\u20A5" U+020A5 (8357) NN MILL SIGN
35: ₦ "\u20A6" U+020A6 (8358) NN NAIRA SIGN
36: ₧ "\u20A7" U+020A7 (8359) NN PESETA SIGN
37: ₨ "\u20A8" U+020A8 (8360) NN RUPEE SIGN
38: ₩ "\u20A9" U+020A9 (8361) NN WON SIGN
39: ₪ "\u20AA" U+020AA (8362) NN NEW SHEQEL SIGN
40: ₫ "\u20AB" U+020AB (8363) NN DONG SIGN
41: € "\u20AC" U+020AC (8364) NN EURO SIGN
42: ₭ "\u20AD" U+020AD (8365) NN KIP SIGN
43: ₮ "\u20AE" U+020AE (8366) NN TUGRIK SIGN
44: ₯ "\u20AF" U+020AF (8367) NN DRACHMA SIGN
45: ₰ "\u20B0" U+020B0 (8368) NN GERMAN PENNY SIGN
46: ₱ "\u20B1" U+020B1 (8369) NN PESO SIGN
47: ₲ "\u20B2" U+020B2 (8370) NN GUARANI SIGN
48: ₳ "\u20B3" U+020B3 (8371) NN AUSTRAL SIGN
49: ₴ "\u20B4" U+020B4 (8372) NN HRYVNIA SIGN
50: ₵ "\u20B5" U+020B5 (8373) NN CEDI SIGN
51: ℃ "\u2103" U+02103 (8451) NN DEGREE CELSIUS
52: ← "\u2190" U+02190 (8592) NN LEFTWARDS ARROW
53: → "\u2192" U+02192 (8594) NN RIGHTWARDS ARROW
54: ⇒ "\u21D2" U+021D2 (8658) NN RIGHTWARDS DOUBLE ARROW
55: ∙ "\u2219" U+02219 (8729) NN BULLET OPERATOR
56: ⌘ "\u2318" U+02318 (8984) NN PLACE OF INTEREST SIGN
57: ☃ "\u2603" U+02603 (9731) NN SNOWMAN
58: ☹ "\u2639" U+02639 (9785) NN WHITE FROWNING FACE
59: ☺ "\u263A" U+0263A (9786) NN WHITE SMILING FACE
60: ☻ "\u263B" U+0263B (9787) NN BLACK SMILING FACE
61: ア "\u30A2" U+030A2 (12450) NN KATAKANA LETTER A
62: 字 "\u5B57" U+05B57 (23383) NN CJK UNIFIED IDEOGRAPHS 5B57
63: 文 "\u6587" U+06587 (25991) NN CJK UNIFIED IDEOGRAPHS 6587
64: "\uF8FF" U+0F8FF (63743) NN PRIVATE USE AREA F8FF
65: 𠀀 "\uD840\uDC00" U+20000 (131072) NN HIGH SURROGATES D840
66: 𪚥 "\uD869\uDEA5" U+2A6A5 (173733) NN HIGH SURROGATES D869More background info: "Java: a rough guide to character encoding"
Scheme
(display (char->integer #\a)) (newline) ; prints "97"
(display (integer->char 97)) (newline) ; prints "a"Seed7
writeln(ord('a'));
writeln(chr(97));SenseTalk
put CharToNum("a")
put NumToChar(97)SequenceL
SequenceL natively supports ASCII characters.
SequenceL Interpreter Session:
cmd:>asciiToInt('a')
97
cmd:>intToAscii(97)
'a'Sidef
say 'a'.ord; # => 97
say 97.chr; # => 'a'Slate
$a code.
97 as: String Character.Smalltalk
($a asInteger) displayNl. "output 97"
(Character value: 97) displayNl. "output a"Ansi Smalltalk defines codePoint
Transcript showCR:$a codePoint.
Transcript showCR:(Character codePoint:97).
Transcript showCR:(98 asCharacter).
'abcmøøse𝔘𝔫𝔦𝔠𝔬𝔡𝔢' do:[:ch |
Transcript showCR:ch codePoint
]- Output:
97 a b 97 98 99 109 248 248 115 101 120088 120107 120102 120096 120108 120097 120098
SmileBASIC
PRINT CHR$(97) 'a
PRINT ASC("a") '97SNOBOL4
Snobol implementations may or may not have built-in char( ) and ord ( ) or asc( ). These are based on examples in the Snobol4+ tutorial and work with the native (1-byte) charset.
define('chr(n)') :(chr_end)
chr &alphabet tab(n) len(1) . chr :s(return)f(freturn)
chr_end
define('asc(str)c') :(asc_end)
asc str len(1) . c
&alphabet break(c) @asc :s(return)f(freturn)
asc_end
* # Test and display
output = char(65) ;* Built-in
output = chr(65)
output = asc('A')
end- Output:
A A 65
SparForte
As a structured script.
#!/usr/local/bin/spar
pragma annotate( summary, "charcode" )
@( description, "Given a character value in your language, print its code (could be" )
@( description, "ASCII code, Unicode code, or whatever your language uses). For example," )
@( description, "the character 'a' (lowercase letter A) has a code of 97 in ASCII (as" )
@( description, "well as Unicode, as ASCII forms the beginning of Unicode). Conversely," )
@( description, "given a code, print out the corresponding character. " )
@( category, "tutorials" )
@( see_also, "http://rosettacode.org/wiki/Character_codes" )
@( author, "Ken O. Burtch");
pragma license( unrestricted );
pragma restriction( no_external_commands );
procedure charcode is
code : constant natural := 97;
ch : constant character := 'a';
begin
put_line( "character code" & strings.image( code ) & " = character " & strings.val( code ) );
put_line( "character " & ch & " = character code" & strings.image( numerics.pos( ch ) ) );
end charcode;SPL
In SPL all characters are used in UTF-16LE encoding.
x = #.array("a")
#.output("a -> ",x[1]," ",x[2])
x = [98,0]
#.output("98 0 -> ",#.str(x))- Output:
a -> 97 0 98 0 -> b
Standard ML
print (Int.toString (ord #"a") ^ "\n"); (* prints "97" *)
print (Char.toString (chr 97) ^ "\n"); (* prints "a" *)Stata
The Mata ascii function transforms a string into a numeric vector of UTF-8 bytes. For instance:
: ascii("α")
1 2
+-------------+
1 | 206 177 |
+-------------+Where 206, 177 is the UTF-8 encoding of Unicode character 945 (GREEK SMALL LETTER ALPHA).
ASCII characters are mapped to single bytes:
: ascii("We the People")
1 2 3 4 5 6 7 8 9 10 11 12 13
+-------------------------------------------------------------------------------+
1 | 87 101 32 116 104 101 32 80 101 111 112 108 101 |
+-------------------------------------------------------------------------------+Conversely, the char function transforms a byte vector into a string:
: char((73,32,115,116,97,110,100,32,104,101,114,101))
I stand hereSwift
The type that represent a Unicode code point is UnicodeScalar.
You can initialize it with a string literal:
let c1: UnicodeScalar = "a"
println(c1.value) // prints "97"
let c2: UnicodeScalar = "π"
println(c2.value) // prints "960"Or, you can get it by iterating a string's unicode scalars view:
let s1 = "a"
for c in s1.unicodeScalars {
println(c.value) // prints "97"
}
let s2 = "π"
for c in s2.unicodeScalars {
println(c.value) // prints "960"
}You can also initialize it from a UInt32 integer:
let i1: UInt32 = 97
println(UnicodeScalar(i1)) // prints "a"
let i2: UInt32 = 960
println(UnicodeScalar(i2)) // prints "π"Tailspin
Tailspin works with Unicode codepoints
'abc' -> $::asCodePoints -> !OUT::write
'$#10;' -> !OUT::write
'$#97;' -> !OUT::write- Output:
[97, 98, 99] a
Tcl
# ASCII
puts [scan "a" %c] ;# ==> 97
puts [format %c 97] ;# ==> a
# Unicode is the same
puts [scan "π" %c] ;# ==> 960
puts [format %c 960] ;# ==> πTI-83 BASIC
TI-83 BASIC provides no built in way to do this, so in all String<-->List routines and anything else which requires character codes, a workaround using inString( and sub( is used. In this example, the code of 'A' is displayed, and then the character matching a user-defined code is displayed.
"ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789→Str1
Disp inString(Str1,"A
Input "CODE? ",A
Disp sub(Str1,A,1TI-89 BASIC
The TI-89 uses an 8-bit charset/encoding which is similar to ISO-8859-1, but with more mathematical symbols and Greek letters. At least codes 14-31, 128-160, 180 differ. The ASCII region is unmodified. (TODO: Give a complete list.)
The TI Connect X desktop software converts between this unique character set and Unicode characters, though sometimes in a consistent but inappropriate fashion.
The below program will display the character and code for any key pressed. Some keys do not correspond to characters and have codes greater than 255. The portion of the program actually implementing the task is marked with a line of “©”s.
Prgm
Local k, s
ClrIO
Loop
Disp "Press a key, or ON to exit."
getKey() © clear buffer
0 → k : While k = 0 : getKey() → k : EndWhile
ClrIO
If k ≥ 256 Then
Disp "Not a character."
Disp "Code: " & string(k)
Else
char(k) → s ©
© char() and ord() are inverses. ©
Disp "Character: " & s ©
Disp "Code: " & string(ord(s)) ©
EndIf
EndLoop
EndPrgmTrith
Characters are Unicode code points, so the solution is the same for Unicode characters as it is for ASCII characters:
"a" ord print
97 chr print"π" ord print
960 chr printTUSCRIPT
$$ MODE TUSCRIPT
SET character ="a", code=DECODE (character,byte)
PRINT character,"=",code- Output:
a=97
uBasic/4tH
uBasic/4tH is an integer BASIC, just like Tiny BASIC. However, the function ORD() is supported, just as CHR(). The latter is only allowed within a PRINT statement.
z = ORD("a") : PRINT CHR(z) ' Prints "a"UNIX Shell
Aamrun$ printf "%d\n" \'a
97
Aamrun$ printf "\x$(printf %x 97)\n"
a
Aamrun$Ursa
# outputs the character value for 'a'
out (ord "a") endl console
# outputs the character 'a' given its value
out (chr 97) endl consoleUrsala
Character code functions are not built in but easily defined as reifications of the character table.
#import std
#import nat
chr = -: num characters
asc = -:@rlXS num characters
#cast %cnX
test = (chr97,asc`a)- Output:
(`a,97)
Uxntal
( uxnasm char-codes.tal char-codes.rom && uxncli char-codes.rom )
|00 @System &vector $2 &expansion $2 &wst $1 &rst $1 &metadata $2 &r $2 &g $2 &b $2 &debug $1 &state $1
|10 @Console &vector $2 &read $1 &pad $4 &type $1 &write $1 &error $1
|0100
[ LIT "a ] print-hex
newline
#61 .Console/write DEO
newline
( exit )
#80 .System/state DEO
BRK
@print-hex
DUP #04 SFT print-digit #0f AND print-digit
JMP2r
@print-digit
DUP #09 GTH #27 MUL ADD #30 ADD .Console/write DEO
JMP2r
@newline
#0a .Console/write DEO
JMP2rOutput:
61 a
VBA
Debug.Print Chr(97) 'Prints a
Debug.Print [Code("a")] ' Prints 97VBScript
'prints a
WScript.StdOut.WriteLine Chr(97)
'prints 97
WScript.StdOut.WriteLine Asc("a")Vim Script
The behavior of the two functions depends on the value of the option encoding.
"encoding is set to utf-8
echo char2nr("a")
"Prints 97
echo nr2char(97)
"Prints aVisual Basic .NET
Console.WriteLine(Chr(97)) 'Prints a
Console.WriteLine(Asc("a")) 'Prints 97V (Vlang)
fn main() {
println('a'[0]) // prints "97"
println('π'[0]) // prints "207"
s := 'aπ'
println('string cast to bytes: ${s.bytes()}')
for c in s {
print('0x${c:x} ')
}
}- Output:
97 207 string cast to bytes: [a, 0xcf, 0x80] 97->0x61 207->0xcf 128->0x80
Wren
Wren does not have a character type as such but one can use single character strings instead. Strings can contain any Unicode code point.
var cps = []
for (c in ["a", "π", "字", "🐘"]) {
var cp = c.codePoints[0]
cps.add(cp)
System.print("%(c) = %(cp)")
}
System.print()
for (i in cps) {
var c = String.fromCodePoint(i)
System.print("%(i) = %(c)")
}- Output:
a = 97 π = 960 字 = 23383 🐘 = 128024 97 = a 960 = π 23383 = 字 128024 = 🐘
XLISP
In a REPL:
[1] (INTEGER->CHAR 97)
#\a
[2] (CHAR->INTEGER #\a)
97XPL0
A character is represented by an integer value equal to its ASCII code. The up-arrow character is used to convert the immediately following character to an integer equal to its ASCII code.
IntOut(0, ^a); \(Integer Out) displays "97" on the console (device 0)
ChOut(0, 97); \(Character Out) displays "a" on the console (device 0)Z80 Assembly
The Z80 doesn't understand what ASCII codes are by itself. Most computers/systems that use it will have firmware that maps each code to its corresponding glyph. Printing a character given its code is trivial. On the Amstrad CPC:
LD A,'a'
call &BB5aPrinting a character code given a character takes slightly more work. You'll need to separate each hexadecimal digit of the ASCII code, convert each digit to ASCII, and print it. Once again, thanks to Keith of [Chibiakumas] for this code:
ShowHex:
push af
and %11110000
rrca
rrca
rrca
rrca
call PrintHexChar
pop af
and %00001111
;call PrintHexChar (execution flows into it naturally)
PrintHexChar:
or a ;Clear Carry Flag
daa
add a,&F0
adc a,&40 ;this sequence of instructions converts a single hex digit to ASCII.
jp PrintChar ;this is whatever routine prints to the screen on your system.
; It must end in a "ret" and it must take the accumulator as its argument.Zig
const std = @import("std");
const unicode = std.unicode;
pub fn main() !void {
const stdout = std.io.getStdOut().writer();
try characterAsciiCodes(stdout);
try characterUnicodeCodes(stdout);
}
fn characterAsciiCodes(writer: anytype) !void {
try writer.writeAll("Sample ASCII characters and codes:\n");
// Zig's string is just an array of bytes (u8).
const message: []const u8 = "ABCabc";
for (message) |val| {
try writer.print(" '{c}' code: {d} [hexa: 0x{x}]\n", .{ val, val, val });
}
try writer.writeByte('\n');
}
fn characterUnicodeCodes(writer: anytype) !void {
try writer.writeAll("Sample Unicode characters and codes:\n");
const message: []const u8 = "あいうえお";
const utf8_view = unicode.Utf8View.initUnchecked(message);
var iter = utf8_view.iterator();
while (iter.nextCodepoint()) |val| {
var array: [4]u8 = undefined;
const slice = array[0..try unicode.utf8Encode(val, &array)];
try writer.print(" '{s}' code: {d} [hexa: U+{x}]\n", .{ slice, val, val });
}
try writer.writeByte('\n');
}- Output:
Sample ASCII characters and codes: 'A' code: 65 [hexa: 0x41] 'B' code: 66 [hexa: 0x42] 'C' code: 67 [hexa: 0x43] 'a' code: 97 [hexa: 0x61] 'b' code: 98 [hexa: 0x62] 'c' code: 99 [hexa: 0x63] Sample Unicode characters and codes: 'あ' code: 12354 [hexa: U+3042] 'い' code: 12356 [hexa: U+3044] 'う' code: 12358 [hexa: U+3046] 'え' code: 12360 [hexa: U+3048] 'お' code: 12362 [hexa: U+304a]
zkl
The character set is 8 bit ASCII (but doesn't care if you use UTF-8 or unicode characters).
"a".toAsc() //-->97
(97).toChar() //-->"a"Zoea
program: character_codes
input: a
output: 97Zoea Visual
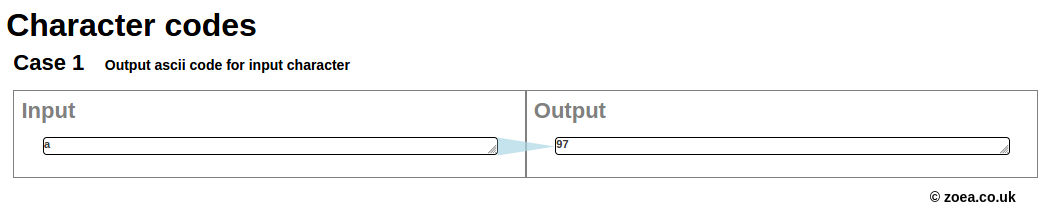{kind=link}
ZX Spectrum Basic
10 PRINT CHR$ 97: REM prints a
20 PRINT CODE "a": REM prints 97- Basic language learning
- String manipulation
- Simple
- Programming Tasks
- Text processing
- 11l
- 360 Assembly
- 68000 Assembly
- AArch64 Assembly
- ABAP
- ACL2
- Action!
- ActionScript
- Ada
- Aime
- ALGOL 68
- ALGOL W
- APL
- AppleScript
- ARM Assembly
- Arturo
- AutoHotkey
- AWK
- Axe
- Babel
- BASIC
- Applesoft BASIC
- BaCon
- Chipmunk Basic
- Commodore BASIC
- GW-BASIC
- IS-BASIC
- MSX Basic
- QBasic
- Sinclair ZX81 BASIC
- SmallBASIC
- True BASIC
- XBasic
- Yabasic
- BASIC256
- Batch File
- BBC BASIC
- Befunge
- BQN
- Bracmat
- C
- C sharp
- C++
- Clojure
- CLU
- COBOL
- CoffeeScript
- Common Lisp
- Component Pascal
- D
- Dc
- Delphi
- Draco
- DWScript
- Dyalect
- E
- EasyLang
- Ecstasy
- Eiffel
- Elena
- Elixir
- Emacs Lisp
- EMal
- Erlang
- Euphoria
- F Sharp
- Factor
- FALSE
- Fantom
- Fennel
- Forth
- Fortran
- Free Pascal
- FreeBASIC
- Frink
- FutureBasic
- Gambas
- GAP
- Go
- Golfscript
- Groovy
- Haskell
- HicEst
- HolyC
- Hoon
- I
- Icon
- Unicon
- Io
- J
- Java
- JavaScript
- Joy
- Jq
- Julia
- K
- Kotlin
- LabVIEW
- Lang
- Lang5
- Langur
- Lasso
- LFE
- Liberty BASIC
- LIL
- Lingo
- Little
- LiveCode
- Logo
- Logtalk
- Lua
- M2000 Interpreter
- Maple
- Mathematica
- Wolfram Language
- MATLAB
- Octave
- Maxima
- Metafont
- Microsoft Small Basic
- MiniScript
- Modula-2
- Modula-3
- MUMPS
- Nanoquery
- Neko
- NESL
- NetRexx
- Nim
- NS-HUBASIC
- Oberon-2
- Objeck
- Object Pascal
- OCaml
- Oforth
- OpenEdge/Progress
- Oz
- PARI/GP
- Pascal
- Plain English
- Perl
- Phix
- Phix/basics
- Phixmonti
- PHP
- Picat
- PicoLisp
- PL/I
- PowerShell
- Prolog
- PureBasic
- Python
- Quackery
- R
- Racket
- Raku
- RapidQ
- Red
- Retro
- REXX
- Ring
- RPL
- Ruby
- Run BASIC
- Rust
- Sather
- Scala
- Scheme
- Seed7
- SenseTalk
- SequenceL
- Sidef
- Slate
- Smalltalk
- SmileBASIC
- SNOBOL4
- SparForte
- SPL
- Standard ML
- Stata
- Swift
- Tailspin
- Tcl
- TI-83 BASIC
- TI-89 BASIC
- Trith
- TUSCRIPT
- UBasic/4tH
- UNIX Shell
- Ursa
- Ursala
- Uxntal
- VBA
- VBScript
- Vim Script
- Visual Basic .NET
- V (Vlang)
- Wren
- XLISP
- XPL0
- Z80 Assembly
- Zig
- Zkl
- Zoea
- Zoea Visual
- ZX Spectrum Basic
- Bc/Omit
- GUISS/Omit
- Pages with too many expensive parser function calls